9.5 KiB
Valutazione delle Prestazioni
Il progetto riguarda un simulatore ad eventi discreti. Il simulatore è iniziato con il lavoro trovato sul libro di testo Discrete-Event System Simulation al Capitolo 4, per poi esser personalizzato e modificato radicalmente.
Il risultato è la creazione in una libreria per la simulazione di eventi discreti nella quale si può scegliera la topologia e la quantità di nodi nella rete da simulare.
Important
Il JAR risultante che si trova nelle Releases.
La versione di Java usata è la 23 (precisamente la 23.0.1).
Comandi Jar
Il JAR viene invocato tramite il classico comando java: java -jar upo-valpre.jar al quale si aggiungono vari argomenti successivi in base a cosa si vuole fare:
java -jar upo-valpre.jar interactive
Usato per avviare una sessione interattiva per la creazione di una rete. Da usare se la rete è relativamente breve da descrivere, altrimenti è più comodo usare il codice della libreria per la generazione della rete.
Una volta scelta la rete è necessario salvarla in un file per la successiva simulazione e analisi.java -jar upo-valpre.jar simulation -net <file> [other]
Usato per avviare una simulazione della rete. Nel caso la rete non abbia eventuali limiti nella generazione di arrivi, viene restituito un errore. Esistono vari tipi di argomenti per scegliere come fare la simulazione:-runs <N>per fare la simulazione N volte-seed <value>per dare un seed iniziale scelto-i <confidences>per scegliere gli indici di terminazione delle run di simulazione quando l'intervallo di confidenza associato è raggiunto. Viene ignorato il comando -p se questa opzione è attiva. Il formato da usare è
[nodo:statistica=confidenza:errore%];[..]-csv <file>per salvare i risultati delle run in un file csv-pper fare le simulazioni in parallelo (ovvero su più thread)-end <criteria>per scegliere quando la simulazione finisce nel caso non ci siano dei source limitati nella creazione di arrivi. La tipologia di fine simulazione la si può trovare dentroEndCriteria(ovvero MaxArrivals, MaxDepartures, MaxTime) e la formattazione da usare per passare il parametro è la seguente:
[tipo:param1,..,paramN];[..]
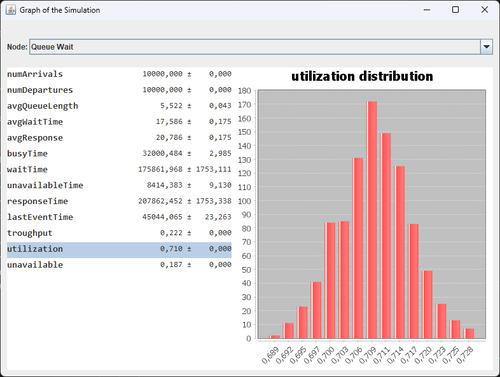
java -jar upo-valpre.jar plot -csv <file>
Mostra (con un ambiente grafico) una finestra nella quale si può scegliere quale nodo vedere e ogni statistica associata ad esso. Di seguito un'immagine di esempio:

Classi Interne
Esistono molteplici classi interne che vengono usate per supportare la simulazione e/o mostrare i risultati. In generale le classi dentro il percorso net.berack.upo.valpre sono usate per l'utilizzo del jar e quindi non sono essenziali per la simulazione. I percorsi che invece sono direttamente responsabili per la simulazione sono:
- net.berack.upo.valpre.rand All'interno del quale si possono trovare:
- Rng che viene usato per il calcolo di numeri pseudo-casuali tramite un seed iniziale e la generazione di molteplici stream di generazione di numeri casuali
- Distribution interfaccia usata per la generazione di un numero casuale di una distribuzione. In questo file esistono molteplici classi interne che implementano l'interfaccia; per esempio: Exponential, Normal, Uniform
- net.berack.upo.valpre.sim Package che contiene tutte le parti utili alla simulazione; per esempio la creazione della rete o la simulazione si più thread:
- Net che viene usato per rappresentare una rete da simulare.
- ServerNode che viene usato per rappresentare un singolo nodo della rete.
- Event che viene usato per rappresentare un evento della simulazione.
- EndCriteria interfaccia che viene implementata dalle classi interne usata per controllare se e quando la simulazione debba finire.
- Simulation e SimulationMultiple che vengono usate per far partire la simulazione; la versione multiple serve ad organizzare molteplici simulazioni su più thread o su un singolo core.
- net.berack.upo.valpre.sim.stats Package che contiene tutte le classi utili per la raccolta e l'analisi statistica dei vari valori generati dalla simulazione:
- Result il risultato di una run e la sua classe interna Result.Summary che contiene molteplici risultati di run già analizzati.
- NodeStats contiene indici statistici di un nodo e la sua classe interna NodeStats.Summary che contiene molteplici indici statistici già analizzati.
- ConsoleTable utile per mostrare i risultati in console sottoforma di tabella
- CsvResult utile per la lettura/scrittura dei risultati in formato csv
Esempi
Nel jar sono presenti già 2 reti per fare degli esperimenti e/o testare se il tool funziona correttamente. Per poter vedere una run usando questi esempi basta far partire il tool in modalità interattiva e scegliere di caricare gli esempi.
java -jar upo-valpre.jar interactive
Questa libreria è stata confrontata con il tool JMT; le reti usate per fare il confronto si possono trovare sotto le risorse del test e in esse ci sono anche i risultati ottenuti dalle run.
Inoltre in alcune istanze state modificate le due reti di esempio in modo da mostrare cosa succede con l'aumento del numero di clienti nel sistema e cambiando la distribuzione di servizio di un nodo. Ogni valore ottenuto ha un sample di 1000 simulazioni. I risultati possono essere presi dal seguente link
Le distribuzioni usate hanno tutte la stessa media μ:
- Normale(μ, 0.6)
- Uniforme(μ - (μ*0.1), μ + (μ*0.1))
- Esponenziale(1/μ)
- Erlang(5, 5/μ)
- Iperesponenziale(p=[0.5, 0.5], e=[1/(μ*0.5), 1/(μ*1.5)])
Primo esempio

Il primo è example1; è una rete composta da una fonte di clienti (Source) che arrivano con tasso esponenziale (λ=0.222 e quindi media 4.5) e un centro di servizio (Queue) con tasso di servizio distribuito come una normale (μ=3.2, σ=0.6).
Se si effettua una simulazione si vedranno i risultati sulla console in questo modo:

Il tool JMT con la stessa rete produce i seguenti risultati che sono molto simili a quelli prodotti dalla libreria:\
Response Time (Queue) 7.3022 con range [7.1456, 7.4589]
Throughput (Queue) 0.2226 con range [0.2182, 0.2271]
Utilization (Queue) 0.7111 con range [0.6959, 0.7262]
Successivamente ho cambiato la distribuzione di servizio usata dal nodo "Queue".
Come si può notare l'utilizzo e il throughput rimangono pressochè invariati tra le varie distribuzioni, ma convergono con l'aumentare dei clienti.
I valori che cambiano sono il numero medio della coda, il tempo medio di attesa e, di conseguenza, anche il tempo medio di risposta.

Di seguito si può vedere il cambiamento del tempo medio di attesa, il numero medio della coda e l'utilizzazione al variare del numero di clienti nel sistema.

Secondo esempio

Il secondo esempio è example2; è una rete composta da una fonte di clienti (Source) che arrivano con tasso esponenziale (λ=1.5 e quindi media 0.666), un centro di servizio (Service1) con tasso di servizio distribuito come una esponenziale (λ=2.0 e quindi media 0.5) e un altro centro di servizio (Service2) con tasso di servizio distribuito come una esponenziale (λ=3.5 e quindi media 0.2857) e con un tempo di indisponibilità che viene attivato con probabilità 10% e distribuito con una eseponenziale (λ=10.0 e quindi media 0.1)
Se si effettua una simulazione si vedranno i risultati sulla console in questo modo:

Il tool JMT con la stessa rete produce i seguenti risultati che sono molto simili a quelli prodotti dalla libreria:\
Response Time (Service1) 2.0115 con range [1.9671, 2.0559]
Response Time (Busy2) 0.2858 con range [0.2816, 0.2899]
Response Time (Queue2) 0.2318 con range [0.2250, 0.2387]
Utilization (Service1) 0.7472 con range [0.7410, 0.7534]
Number of Customers (Busy2) 0.4285 con range [0.4248, 0.4322]
Number of Customers (Calibration) 0.0149 con range [0.0148, 0.0151]
Throughput del Sistema 1.5094 con range [1.5005, 1.5183]
Successivamente ho cambiato la distribuzione di servizio usata dal nodo "Service2".
Anche in questo caso l'utilizzo e il throughput rimangono pressochè invariati e convergono con l'aumentare dei clienti nel sistema, ma cambiano il numero medio della coda e il tempo medio di attesa.
Una particolarità di questa rete è il basso valore atteso per il tempo di servizio. Questo, in concomitanza con il resample in caso di valori negativi, fa si di aumentare la media della Distribuzione Normale. Nei grafici seguenti è stata inclusa la Normale solo nell'ultimo per mostrare la differenza rispetto le altre distribuzioni.
